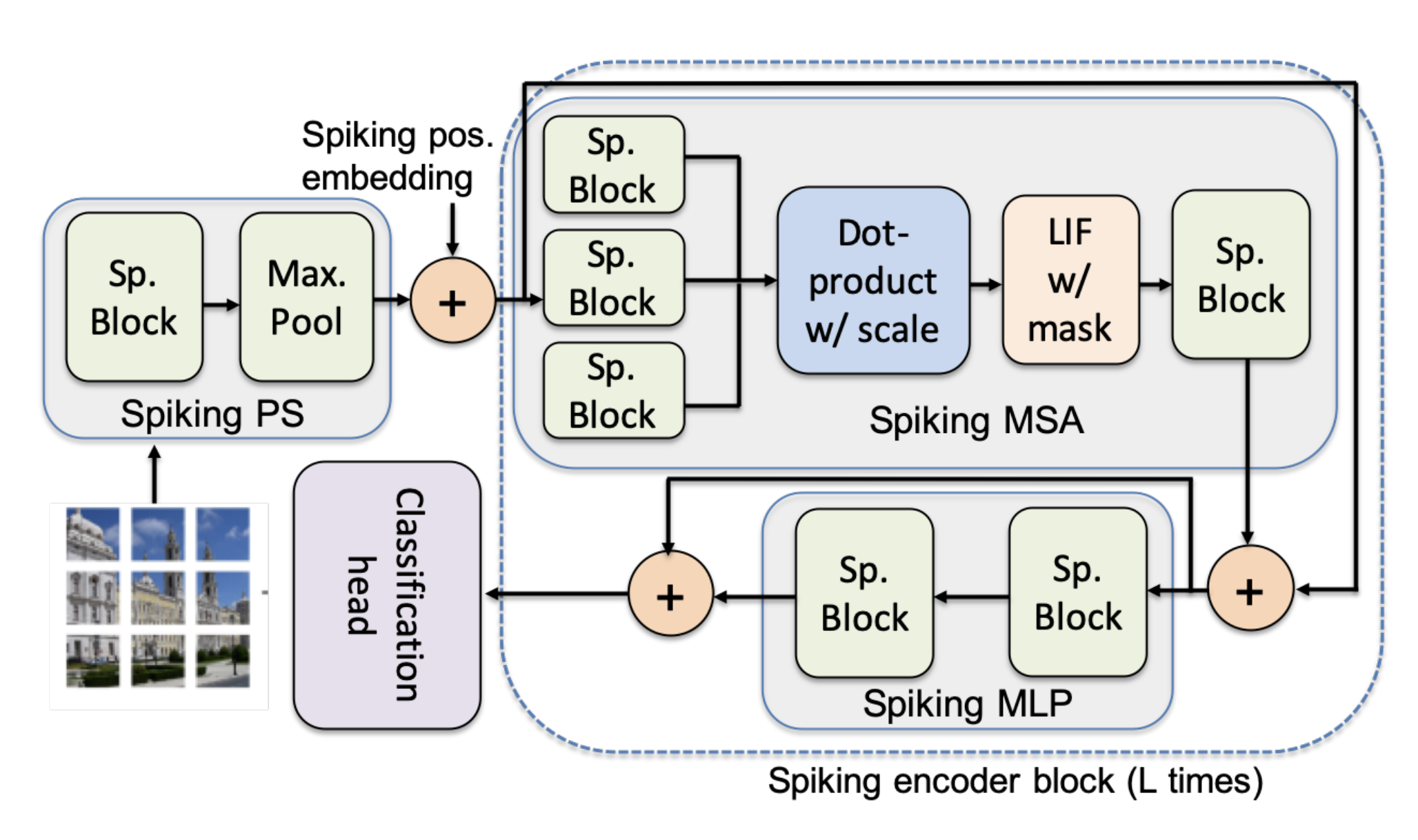
Overview
VitSNN introduces a dynamic time step allocation framework for Vision Transformers in Spiking Neural Networks, achieving high accuracy with significantly reduced computational requirements through adaptive spike filtering and efficient operations.
Highlights
- Developed a novel training framework for dynamic time step allocation in ViT-based SNNs
- Achieved 95.97% test accuracy on CIFAR10 with only 4.97 time steps
- Implemented efficient accumulate operations (AC) instead of MAC operations
- Demonstrated high activation sparsity for improved energy efficiency
Architecture
- Dynamic Time Step Allocation: Trainable score-based time step assignment
- Binary Time Step Mask: Filters spikes from LIF neurons
- Efficient Operations: AC-based computations for most layers
- ViT Integration: Modified Vision Transformer blocks for SNN compatibility